Building a programming language from scratch
programming language interpreterPreface
Amir from the future here! This blog post documents my journey from not knowing what the hell Lisp was, to creating a Lisp-dialect (i.e. a programming language that is a dialect of Lisp) inspired by Scheme and Clojure. Below you’ll find my “journal” throughout the process. You can find more technical details about the project repo on GitHub.
You can also learn more about the language and run it your browser here.
Why have a journal?
Miley Cyrus said it best when she said
ain’t about how fast you get there, ain’t about what’s waiting on the other side, it’s the climb.
In other words, journey before destination. I think with many projects, we often only see the end result and not the struggle / journey in between, so I figured showing the process from being a complete noob to a little less of a noob might be helpful to other people who potentially want to try their hand at doing something like this.
Motivation
Nowadays, software powers so much of the world. There’s so much going on that sometimes, it’s easier to convince yourself that something cannot be understood. I do not consider myself a great programmer. In fact, I’d describe myself as a below average to average programmer. What I do try to do is be unintimidated by software. If building an interpreter or designing your own programming language is something that sounds at all interesting, do not be intimidated. In Nelson Elhage’s essay “Computers can be understood” there is a great section on just this.
I approach software with a deep-seated belief that computers and software systems can be understood. In some ways, this belief feels radical today. Modern software and hardware systems contain almost unimaginable complexity amongst many distinct layers, each building atop each other. In the face of this complexity, it’s easy to assume that there’s just too much to learn, and to adopt the mental shorthand that the systems we work with are best treated as black boxes, not to be understood in any detail. I argue against that approach. You will never understand every detail of the implementation of every level on that stack; but you can understand all of them to some level of abstraction, and any specific layer to essentially any depth necessary for any purpose.
In short, do not be afraid of taking on a technical project that seems out of your depth or too challenging. In fact, the more challenging a project is, the more rewarding it will be. So just dive in, you can figure out the details later
Journal
Today, I’m going to start working on a new project: I’m going to build my own programming language from scratch.
In many projects, we often only see the final result, we don’t the see the journey and struggles in the middle (which as I repeatedly mention in my internship post is what’s invaluable) so I’m going to document my process in detail.
- Day 1
- Day 2
- Day 3
- Day 4
- Day 5
- Day 6
- Day 7
- Day 8
- Day 9
- Day 10
- Day 11
- Days 12-13
- Day 14
- Days 15-26
- Days 27-28
- Day 29
- Day 30
- Days 31-33
- Day 34
Day 1
Technically speaking, my experiences with programming languages are quite limited. I have followed the Let’s Build an Interpreter From Scratch for the first ~8 episodes so I’m broadly familiar with the high level components of an interpreter. We have a lexer which is used to convert our code or text into individual tokens, we have a parser to figure out what the tokens are (is this a function declaration, is this an operation, is this a number etc.), we have an interpreter to then do what is asked of us (i.e. call this function, do this operation etc). We have lexical grammars which specify the rules for how we interpret the language.
I also know that many programming languages create an abstract syntax tree from the language and that doing some kind of traversal on the tree is how we then figure out what to actually do from the source code. To figure out the map from the territory, Linus’s post has been helpful. As of right now, I’m not sure what type of language to create. Should I explore functional programming, similar to Lisp? Should I explore concurrency? Should I explore memory allocation or readability? I don’t know.
I’m going to start working through Crafting Interpreters and get a better picture of the map. I’ll figure out what later. I’m going to write the language in Go because, although I’m more proficient in Python, I like Go from my experience building athena, carly, and vibely. So I’m going to run with it. Also because Go compiles code into a single executable which can be run anywhere, it’s more likely I’d be able to take advantage of this down the line if I wanted to use my language to build and ship other side projects.
Update, I’m switching to Writing an Interpreter in Go. Since I’m familiar with the high-level ideas, I want to make sure I follow good practices for how to build the language in Go - since it’s not as object-oriented as Java, I don’t want to start off the bat with bad practices.
Let’s get into lexical anaylsis.
Things that have been simplified that will need to be adapted
- Attach filenames and line numbers to tokens (to track down errors more easily)
What I did today:
- Laid foundation for lexer
- Defined token and initial simple list of token types
- Wrote a test to make sure our nextToken function in our lexer correctly works.
Day 2
I’ve decided I want to explore functional programming with my programming language, taking from Lisp. Specifically, I think I’d like it to have a similar flavor to Clojure. Given that I also don’t know Lisp or Clojure, I’m going to hold off on building the interpreter and do some research about the language, how it works, why it’s so powerful, and really get into the meat of the design of the language.
We’re starting here
-
Clojure = modern dialect of Lisp
-
Runs as a hosted language on the Java Virtual Machine (and other platforms)
-
Opinionated approach (different to Java, C++, similar to Javascript)
-
Lots of brackets, strips away most other syntax (no special characters, no operator overloading, no semi-colons) - pure minimalism
-
Main theme: Every piece of source code is a definition of an executable tree structure
- Writing in Clojure = defining nested branches of the tree, identified by brackets called S-expressions
-
Operations first - prefix notation
-
One rule no exceptions
(function param1 param2... paramN) -
Variables don’t really exist in Clojure
-
Core concept: Symbols
- Used to name things - can be bound to value
- Like variables but immutable - bound to fixed value which cannot be changed after definition
- Omits need for core object-oriented concepts like encapsulation
-
Clojure data is immutable by default
-
Functions first class entities, treated like any data/type
-
Functions which consume or produce other functions Higher Order Functions (similar to higher order components)
-
namespaces = similar to modules
-
Vars = named storage containers with out data (called anywhere from namespace)
- different from a variable which is direct mapping from symbol to data
- symbols map to var objects which then can access data
- Defined with def
(def a 4) -
(if test true__expression false_expression)
-
In Clojure, data = code and code = data
- Referred as homoiconicty, lends itself to metaprogramming or code generation which is why Lisp and Lisp variants are so powerful
-
To evaluate data as data, symbolically, use quote or '
-
Lists don’t allow direct access to any other elements (only access at head)
-
Vectors
- More traditional list-like structure similar to arrays or lists in other languages
Did a lot of research today. It turns out designing a programming language is a much more complex process than simply building an interpreter or compiler. In order to make concrete progress, I’m going to break this into sub-goals.
- I want to better understand Lisp / Clojure
- I want my newfound understanding to help me architect my language
To accomplish 1, I’m going to start by building a Lisp interpreter in Go. To do that I’m going to complete the make a lisp interpreter from mal.
Setting everything up took ages, at least 3 hours. Felt like a big time noob learning about how to use makefiles for the first time.
Day 3
I want to iterate quickly and I don’t want to get bogged down. So I’m to going to get started building the lisp interpreter in the easiest way possible here. Only difference is I’ll implement it in Go. Hardest part has been to start doing it. It’s infinitely easier to keep finding the best place or way to get started. There is no best way. The best way is whatever gets you started, so I’ll swallow my own pill and get started. Some motivation has been this
“Compilers take a stream of symbols, figure out their structure according to some domain-specific predefined rules, and transform them into another symbol stream.”
- Numbers & Symbols (a for example) & operators (e.g. >, +, -) are atomic expressions
- Can’t be broken up
- Everything else is a list expression (….) with …. being some list of things
- Special form list = one that starts with a keyword like if (meaning depends on keyword)
- List that with starts with a Non-keyword = a function
- 5 keywords and 8 syntactic forms
Task 1: Implement a simple lispy calculator
Update: The tutorial was very interesting but many core features were implemented with python abstractions that did the heavy lifting. Go is more low-level so doing this kind of thing would not transfer easily. I’m now going back to crafting interpreters + reverse engineering Ale to help guide me. The crafting interpreters narrative is helping cement the fundamentals while the Ale source code will be a good tool for bridging some of the more complex parts.
So slight pivot, I’m basically gonna do this from first principles now. Using all of the resources to help orient and guide me but, I want to build every layer from the ground up.
Key point about context-free grammars
- Distinction between
- lexical analysis
- comprised of characters which form tokens or lexemes
- implemented by a scanner
- syntactic grammar
- comprised of tokens which form expressions
- implemented by a parser
- operates on the outputs of the scanner
- lexical analysis
To write grammar, compromised of
-
terminals (literals, can’t be simplified down further e.g. 205)
-
nonterminals (potentially other expressions which can be called/nested)
-
Need to apply precedence clearly to avoid ambiguity in the parsing → same expression producing different syntax trees and thus different code
What needs to be done:
- First create a list of tokens - this is the Scanner’s or Lexer’s job
- Then onto parsing, given this list of tokens, construct the abstract syntax tree based on the grammar specified
- For our simple lisp interpreter, this means when we see a “(”, we have a new expression so we would need to “recurse” or “nest” our result!
Day 4
Made progress on lexer/scanner and parsing to tokens works. Still not entirely sure how to implement the parsing in Lisp - I found a potential grammar to work with, but we’re still trying to figure things out.
Resources being used:
- https://github.com/kode4food/ale
- https://github.com/glycerine/zygomys
- https://github.com/sunzenshen/go-build-your-own-lisp
Lisp/Clojure recall has Symbols, Numbers, Atoms , List, Expr, Env
- Symbol is `[anything here]
- Numbers is self-explanatory
- Atoms = blocks of independent data
- Lists = starts with a ( followed by 0 or more items
- First item may be an operand, function call, variable etc. But always comes first
Good summary of Lisp
I’m trying to find a grammar to work with for lisp and a possible implementation to get inspiration but things are very scattered. Debating whether I should just dive in or keep looking. I think diving in would be the better and possibly harder option, which is why I keep trying to see how it’s been implemented by others. The problem I’m having is that for Lisp specifically (less so more broadly, but especially for Lisp), I haven’t bridged the gap with exactly how the lexer interfaces with the parser. I think this is because I don’t know exactly how to handle a list - my intuition is that we represent the actual data of the as well as an operation so something like
type ListOperator struct {
operator TokenType
data []byte
}
Looks like S-expression are handled as an interface. I’m going to run with it.
Day 5
I was struggling in the morning but we finally made some progress! I’m building the calculator bit of Lisp at the moment and I have a working parser for simple expressions like (+ 2 5) or (+ 2 (+ 2 5)).
I’m officially making progress now. Diving in head first made me make naive assumptions, however when I was forced to start thinking about how to improve on them, I was able to appreciate what some of the other Lisp interpreters were doing. Now I’m updating the parser and it’s off to the races (for now).
Parser is done, now the struggle has shifted to the evaluating section. Similar problem here, I don’t know how to handle these lists. Normally, the nodes would consist of things like binary operations, unary operations, assignments, function calls - all of which you evaluate the children then do the operation at the parent node. In the list implementation, the operator will be the first term of the list and every other term needs to have this operation carried on it. E.g. (+ 5 3 2) ⇒ 5 + 3 + 2. And our AST’s underlying structure looks like List: {Symbol, Number, Number, ….} for example
- https://github.com/aki237/ligo/
- Was helpful for figuring out evaluation
- https://github.com/zhemao/glisp
- Was helpful for figuring out parsing
Edit: finally got the calculator to work after many hours. Tomorrow is going to be adding state, bindings, and possibly conditions :) Things have been hard, partly because I’m thinking from first-principles, partly because of gaps in my knowledge that I have to fill as I do research (e.g. today I learned about closures, type assertions, and concurrency in Go), but it has been rewarding.
Also, you can follow along my progress here!
Day 6
- Distinction between expressions and statements. Expressions evaluate to smt, statements, depending on the language (e.g. in many functional languages) do or don’t
- Environment = data structure used to associate variables/functions with their values
- Boils down to basically a hashmap
- Scope and environment are close cousins, environment is the machinery that implements scope
- Scope implemented like linked list - start in current scope and check, then get environment of next highest scope (each env has one reference to its parent scope) then check and so on and so forth
- Pattern of defining a node in the syntax tree for handling different types (unary op, binary op, assignment, function) then having a visitor with an interpret method in evaluating where you put domain-specific code
Things to work on today
- State with variables
- Expanding expressions with truth, false, and statements that evaluate to these expressions e.g. (< 5 2) = false
So I just added a data structure to encapsulate environment but I think I need to adapt my old code for how I was handling calculations. For example, a definition in lisp e.g. def a 5 def is a symbol. But it’s logic should take the key it gives it and the value and store it in the hashmap. How am I supposed to handle the different functionality with my current code, where when I evaluate a symbol, I always assume it’s a binary operation so it should return an int? I’m not exactly sure without lots of different functions and lots of casting which, I get the impression, is probably not best practice. I think I’ll implement it like that for now and refactor later.
Looks like the intuition was right inspecting some of other people’s code. I need to encapsulate the logic and only return a result when evaluating the nodes, as opposed to returning a function which then carries the operation out at the node.
Refactored the code and things are starting to make sense! Now adding additional functionality should be more straightforward :)
Added state! Well for variables with integers and strings right now.

Added relational operators, logical operators, and truthiness!
Edit - added conditional statements and println, with some bug fixes. All in all, a solid day. Tomorrow we’re gonna get real with functions and then it’s off to the races.
Day 7
- Lists in Lisp are implemented as a linked list of cons cells
- Need a wrapper (class or struct) to hold the function and then a different one to actually call the function
- Don’t want runtime phase to bleed over to parsing
I spent the morning properly learning about concurrency (as well as a host of other non-interpreter related things). I feel a little bit overwhelmed by my ignorance right now lol. I’d made an assumption that I thought screwed up everything but it was only a small fix away so I feel a little better. But still very stupid. Anyway, let’s keep learning.
Handling floats is turning out to be non-trivial and quite tedious. It’s a polymorphic nightmare but we’re finally done! After lunch, we’re gonna tackle functions (and hopefully reading in from a file and not just the repl)
Solid progress made on functions, but not quite done. Hopefully will finish it up tomorrow!
Day 8
Annnnd functions work! Now I need to make sure scope works correctly and do a lot of testing. I’m going to first work on reading from an external file so I can write more complex code to test this works. Here’s the historic moment of the first function running in Lispy :)
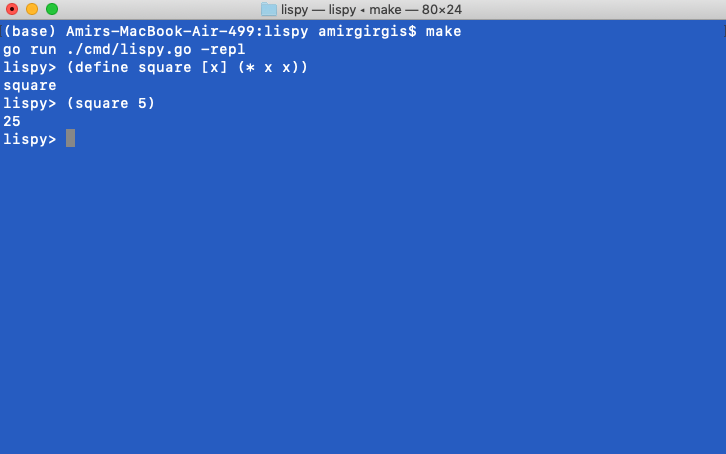
- Adapt ReadFile approach to a buffered approach (reference) since read all puts the entire file in memory
Trying to make recursion work now and the insight is that each function call needs its own environment, which makes sense because each function call is going to pass its own unique set of arguments. I need to clean up how I treated functions, I’d made some assumptions that need to be cleaned out now.
In the process of trying to fix things, I broke them. Sigh. Two steps forward, one step back.
Edit: I may have just found a weird edge case, I should really write tests after every new feature because I just end up backtracking to fix bugs in other features.
Fixed the bug and recursion now works!
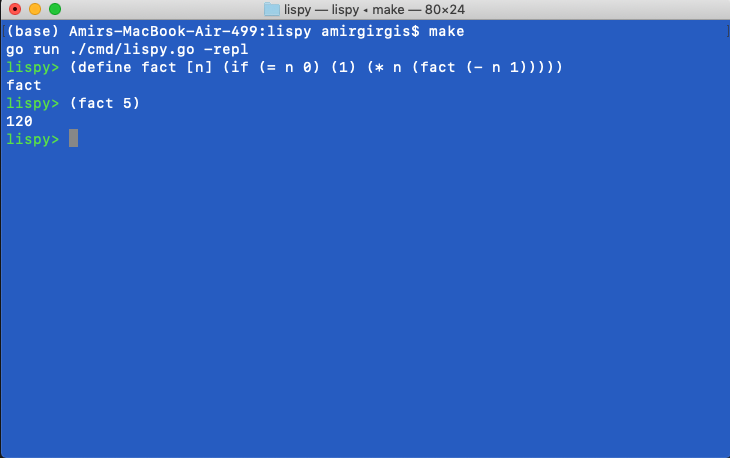
Day 9
Today has been fixing a lot of bugs. There was a sneaky one which took me at least an hour - for some reason the gcd algorithm was not working, gcd(a, b) kept returning b. After about an hour, I realized what was happening was that the wrong parameters were being passed into the recursive call later. 30 minutes later, I figured out that it was because I was overwriting b in my environment so the recursive call was using the new b instead of the old one! So I changed my code to evaluate ALL expressions first before writing them to the env and….
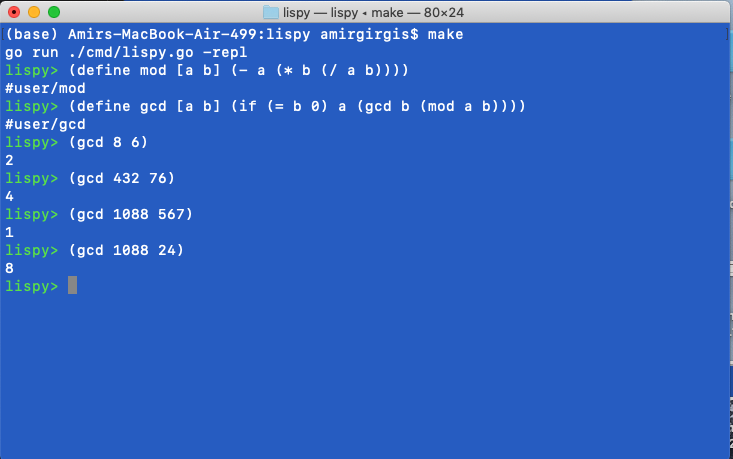
Fixed lots of bugs, tomorrow I’m going to dig into macro and cons.
Gist - macro allow us to directly operate on the language - takes syntax which it treats as data, and allows us to transform it into other syntax (which it returns) which is then run as code.
Remember as it’s been code and regarded with Lisp in general - () with a symbol in the bracket means call to a function! So if you want to return a variable, omit the brackets directly
Some basic operations I’ll need to implement in order to make this happens:
- CAR - takes a list, returns first item of the list
- CDR - removes first element from a list and returns the remaining list
Day 10
Was running into some issues today which I thought were bugs but turned out to be me forgetting how Lisp works and how I’d built the interpreter (symbol within a bracket corresponds to a function call!)
For dealing with functions -
Symbols ≠ strings - stored as cons
- Cons = stores car and cdr, or head and tail
- Atoms and lists are the basic data structure
- Atom = anything that is not a cons cell
To make macros work:
- CAR, CDR
Day 11
I’d previously implemented lists under the hood as arrays of Sexp tokens. However, when I came to start implementing some of the native functions of Lisp like car, cdr, and cons, I noticed that it caused some issues. Lisp is derived from these axioms so to try to implement it as accurately as possible, I decided to rewrite how I handled lists to be a linked list of cons cells. The issue I’m running into is I don’t know, when it comes to evaluation, to handle them consistently. Do I create a list of Sexp tokens? Do I just pass the head of the linked list and have the functions traverse them? In order to keep it consistent, I think the move might be to pass all arguments as an array of Sexp []Sexp and then when I need to handle the cons on a more granular level (e.g. with car when accessing the head), I can just assert the type to be that.
Also want to consolidate how I handle functions - all common header and store native ones in the environment (as opposed to manually handling it in eval which is what I’m doing right now)
So yesterday I was literally drowning in tens of errors trying to switch my implementation and it was incredibly frustrating. And finally, today I’m back to where I was before with lists implemented as a linked list of cons cells instead of a Go array. Now I’m going to work on a) consolidating all my functions to be handled in a consistent way where I can store them in the environment and 2) start working on macros by first implements cons, car, and cdr. The latter should be significantly easier with my current implementation since these definitions follow nicely from the idea of cons cells.
Days 12-13
Implemented car and cdr today. Also did cons but still many bugs to fix. These days, I felt pretty unmotivated.
Day 14
Decided I wanted my final deliverable to be a playground on the web where you can run lispy code and also concretized what needed to still be done in the language. I implemented macros today and continued to find and fix bugs - now we’re writing small programs in Lispy!
Days 15-26
Decided I wanted my final deliverable to be a playground on the web where you can run lispy code and also concretized what needed to still be done in the language. I implemented macros today and continued to find and fix bugs - now we’re writing small programs in Lispy!
Days 27-28
We’re coming up on the end of project. The next thing I want to implement is tail call optimization (since all loops are done recursively). I had to reformat the logic for my eval.go file so I ended up creating a new branch called experiments in case I screwed things up. My solution ended up being quite similar to this where I built a wrapper that turned recursive functions into a flat for loop structure. I may write a technical blog post detailing how I did this but the post I attached (and this one) does a pretty good job at explaining it. The last thing to do is writing a simply Lispy interpreter written in Lispy iteself (Yes it’s interpreter-ception)! Ok actually I lied, the last thing is to write up some proper documentation smh.
Day 29
Was battling with some nasty bugs today and I’m not satisfied with how long it took to fix the issues. On the bright side, I made some solid progress on the metacircular lispy interpreter written in lispy, although I’m still not sure how “complete” I want it to be.
Day 30
Today I worked on (and effectively finished) the landing page for the website for Lispy! I’ll get back on the metacircular interpreter tomorrow but it’s basically ready to share at this point.
Days 31-33
Working on the metacircular interpreter has been kind of frustrating but also really magical. I understand why the die-hard Lispers scream from the roof top that Lisp is amazing, it really has fundamentally changed the way I think about programming. Anyways, I added a simple environment and functions to the metacircular interpreter today. I’m going to wrap things up and share it soon!
Day 34
Share :) To the 🚀